Accelerating the Configuration Tuning of Big Data Analytics with Similarity-aware Multitask Bayesian Optimization
Abstract
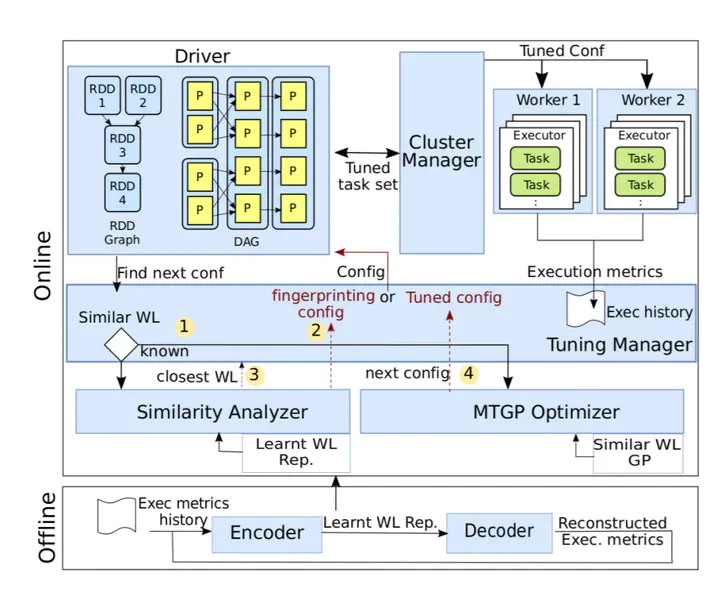
One of the key challenges for data analytics deployment is configuration tuning. The existing approaches for configuration tuning are expensive and overlook the dynamic characteristics of the analytics environment (i.e. frequent changes in workload due to receiving evolving input sizes or change in the underlying cluster environment). Such workload/environment changes can cause significant performance degradation, with retuning the configuration to accommodate those changes can yield up to 85% potential execution time saving. We propose SimTune, an approach that accommodates such changes through efficient configuration tuning. SimTune combines workload characterization and Multitask Bayesian optimization to identify similarity across workloads and accelerate finding near-optimal configurations. Our experimental results show that SimTune reduces the search time for finding close to optimal configurations by 56-73% (at the median) when compared to existing state-of-the-art techniques. This means that the amortization of the tuning cost happens significantly faster, enabling practical tuning in the rapidly changing environment of distributed analytics.