Biography
In September 2026, I will join the University of Oxford as an Associate Professor. I am an Assistant Professor in the Department of Computer Science at the University of British Columbia. I am affiliated with the UBC Security & Privacy Group and the Systopia Lab, UBC’s systems research group. My work focuses on the design and implementation of computer systems that are inherently secure, observable, and transparent. My research interests include system auditing and accountability, intrusion detection, and performance optimization.
En septembre 2026, je rejoindrai l’Université d’Oxford en tant que professeur associé. Je suis professeur adjoint dans le Département d’informatique de l’Université de la Colombie-Britannique (UBC). Je suis affilié au Security & Privacy Group de l’UBC et au Systopia Lab, le groupe de recherche en systèmes de l’UBC. Mes travaux portent sur la conception et la mise en œuvre de systèmes informatiques intrinsèquement observables et transparents. Mes intérêts de recherche incluent l’audit et la responsabilité des systèmes, la détection d’intrusion et l’optimisation des performances.
- Computer Security
- Intrusion Detection
- Digital Provenance
- Operating Systems
- Distributed Systems
- Data Protection and Privacy
-
PhD in Computer Science, 2016
University of Cambridge
-
MPhil in Advanced Computer Science, 2012
University of Cambridge
-
Diplôme d'Ingénieur (apprenticeship), 2011
Institut Supérieur d'Electronique de Paris
-
Diplôme Universitaire de Technologie (apprenticeship), 2008
Conservatoire National des Arts et Métiers
Experience
Joining my lab
Visiting Students and Collaborations
I have had excellent experiences hosting visiting students and am always happy to consider new visits to my lab. Before reaching out, please review our current research and identify a clear alignment with your interests. Your message should include a concrete and feasible plan for the visit: the research question you would like to pursue, the expected timeline, any relevant funding arrangements, and how the collaboration would fit with our group’s work.
Contacting me
If you are planning to apply, please, do so through the Oxford application system. I cannot process and will not review application packages sent by e-mail. I am happy to comment on your research proposal and its alignment with my research. However, I will not discuss your chances of admission.
Please feel free to contact me, but be specific and concise when doing so.
I welcome students from all backgrounds. First-generation students and students from underrepresented or marginalized groups are especially encouraged to apply. Please visit the prospective applicants pages on the Oxford website and the Computer Science website. You can also find information about the cost of living in Oxford.
A few facts
- A DPhil at Oxford is equivalent to a PhD.
- You must apply online.
- Your choice of college does not affect your ability to work with me.
- Departmental admission and studentship/scholarship decisions are made in two separate phases.
- You may be eligible for EPSRC funding through the department.
- You should also apply separately for scholarships; see the British Council scholarship page and Oxford’s fees and funding page.
- Be proactive in applying for scholarships.
- You should apply for scholarships as early as possible.
Before applying
- Understand the many roles of a PhD advisor.
- Review my publications.
- Identify areas where our research interests align.
- Note that I will not supervise students outside my areas of expertise.
- Find a set of papers that align with your interests.
- Read their abstracts.
- Read at least a few of them in full.
Selected Publications

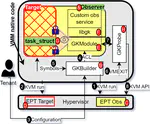
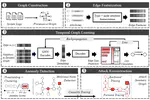
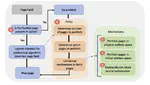
Recent Publications
Teaching
| UBC | ||
|---|---|---|
| CPSC 538P: Introduction to Research in Security & Privacy | 2025-2026 | Winter 2 (January) |
| CPSC 313: Computer Hardware and Operating Systems | 2025-2026 | Winter 1 (September) |
| CPSC 538P: Topic in Computer Systems: Systems Security | 2024-2025 | Winter 2 (January) |
| CPSC 436A: Operating Systems Design and Implementation | 2024-2025 | Winter 1 (September) |
| CPSC 538S: Accountable Computer Systems | 2023-2024 | Winter 2 (January) |
| CPSC 436A: Operating Systems Design and Implementation | 2023-2024 | Winter 1 (September) |
| CPSC 538P: Topic in Computer Systems: Systems Security | 2022-2023 | Winter 2 (January) |
| CPSC 436A: Operating Systems Design and Implementation | 2022-2023 | Winter 1 (September) |
| Bristol | ||
|---|---|---|
| COMS20012: Computer Systems B (Operating Systems & Security) | 2020-2021 | TB2 (January) |
| COMSM0050: Systems and Software Security | 2020-2021 | TB1 (September) |
| COMSM1500: Systems Security | 2019-2020 | TB1 (September) |
| COMSM1500: Systems Security | 2018-2019 | TB1 (September) |
Service
Program Committee
- IEEE S&P 2026
- ACM ASPLOS 2021 (ERC), 2025, 2026
- ACM EuroSys 2020, 2023, 2025, 2026, 2027
- USENIX Security 2024, 2025, 2026
- ACM CCS 2022, 2023, 2026
- ACM REP 2023, 2024
- ACM SOSP 2023
- ACM SoCC 2023
- IEEE EuroS&P 2023
- ACM/IFIP Middleware 2023
- IEEE IC2E 2021, 2022
- ACM M4IoT 2016, 2017, 2018, 2019, 2020, 2021
- USENIX TaPP 2017, 2019, 2024
- IEEE CLAW 2016, 2017, 2018
Reviewer/External
- ACM CCS 2020
Organization
Students & Postdocs
Current Students and Postdocs
- Tristan Bilot (Postdoc, UBC)
- Soo Yee Lim (PhD student, UBC)
- Xuechun Cao (PhD student, UBC)
- Cathy Liu (MSc Student, UBC)
Past students and position held after graduation
- Tanya Prasad (MSc student, UBC), 2025, Software Engineer, Amazon AWS.
- Baoxiang Jiang (Visiting PhD Student, Xi’an Jiaotong University), 2025.
- Tristan Bilot (Visiting PhD Student, Université Paris-Saclay), 2024.
- Nichole Boufford (MSc student, UBC), 2024, Software Developer, Oracle Labs.
- Jinyuan Liang (MSc student, UBC), 2024, Security Analyst, WeBank.
- Haley Li (MSc student, UBC), 2024, co-supervised with Mathias Lécuyer, Research Engineer, Huawei Canada.
- Wellison Raul Mariz Santos, (Visiting PhD Student, UFPE) 2024, Researcher and Professor, CISSA/CESAR.
- Mayank Tiwary (MSc student, UBC), 2023, co-supervised with Ivan Beschastnikh, Senior Member of Technical Staff, Salesforce.
- Bogdan Stelea (MEng, Bristol), 2021, Software Engineer, Amazon.
- Josh Turner (MEng, Bristol), 2021, Software Engineer, Amiosec.
- Chetankumar Mistry (MEng, Bristol), 2020, Software Engineer, ARM.
- Xiaoxiao Wu (MSc, Bristol), 2020, Consultant, Deloitte.
- Yangyang Teng (MSc, Bristol), 2019, Data Analyst, Bloomberg.
- Ziying Shao (BSc, Bristol), 2019, UG Researcher, Beijing Institute of Big Data Research.
Contact
- tfjmp@cs.ubc.ca
- Office 301, 2366 Main Mall, Vancouver, British Columbia V6T 1Z4
- DM Me