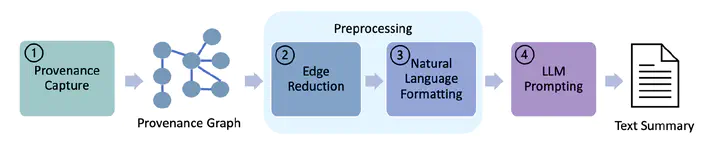
Abstract
Scientists use complex multistep workflows to analyze data. However, reproducing computational experiments is often difficult as scientists’ software engineering practices are geared towards the science, not the programming. In particular, reproducing a scientific workflow frequently requires information about its execution. This information includes the precise versions of packages and libraries used, the particular processor used to perform floating point computation, and the language runtime used. This can be extracted from data provenance, the formal record of what happened during an experiment. However, data provenance is inherently graph-structured and often large, which makes interpretation challenging. Rather than exposing data provenance through its graphical representation, we propose a textual one and use a large language model to generate it. We develop techniques for prompting large language models to automatically generate textual summaries of provenance data.We conduct a user study to compare the effectiveness of these summaries to the more common node-link diagram representation. Study participants are able to extract useful information from both the textual summaries and node-link diagrams. The textual summaries were particularly beneficial for scientists with low computational expertise. We discuss the qualitative results from our study to motivate future designs for reproducibility tools.